AI for noobs: How machine learning works
If you’re here, it means that you’ve succumbed to the madness of AI and have finally made a decision to see how it all works. There are many explainers out there, but I feel like most are too simplistic with buzz-wordy sounding terms or dive too deep without providing good intuition. I hope I can thread that needle and provide a good primer for noobs that I wish I had when I started. By the end of this article, you should have a rough understanding of how all these terms like AI, machine learning, neural networks, large language models etc.
I’m far from being an expert, and if you want a deeper dive into the mechanics I’d highly recommend this course here. It’s relatively doable with some basic Python and a willingness to dig through differential calculus.
Part 1: IT’S EVERYWHERE
You can’t avoid it at this point. Despite the endless cycles of hype and bust, this time it’s different. There has never been a product that has been adopted so quickly before - and for good reason. It’s one of those rare applications that present real use cases from day 1. The AI rampage is going to continue, with its bleeding edge piercing through every conceivable frontier.
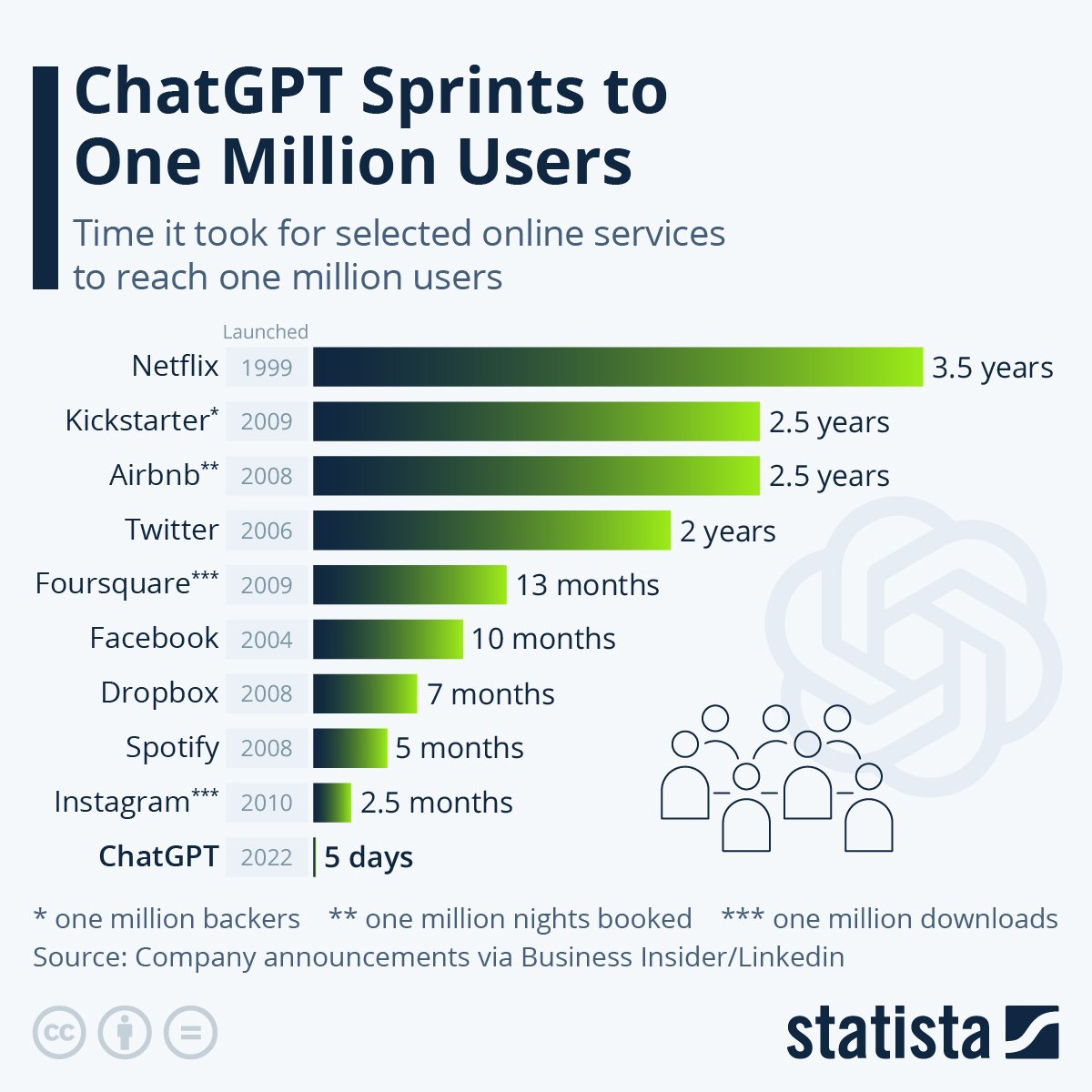
Part 2: What is intelligence?
First, we take a step back and venture into the world of algorithms.
An algorithm, or a function, is simply a set of instructions that takes some input, performs a series of steps, and provides an output. It’s like following a baking recipe. First, you put different amounts of ingredients (input), follow the series of steps in the recipe (algorithm), and you will get a cake (output). That’s a basic algorithm for cake baking.
If intelligence is the ability to solve complex problems, Artificial Intelligence is a way of using algorithms to solve problems that would usually require human intelligence.
Part 3: How traditional programs worked
So we’ve known how to create algorithms for a long time. All our computer programs are essentially sets of algorithms layered on each other.
In traditional programming, instructions have to be explicitly written by the programmer. So if you were to write an algorithm to identify cats in pictures, the steps would look something like this:
Break the image down into a matrix of pixel values
Write extremely complicated steps to recognize certain patterns based on pixel values
Output a probability of the image being a cat
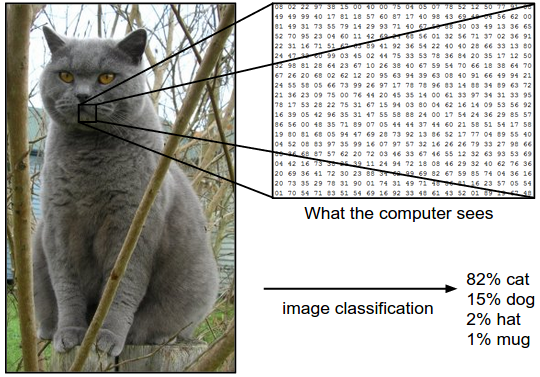
Source: https://machinelearning.technicacuriosa.com/introduction-to-computer-vision-part-1/
There are infinite ways a cat ear can look (multiple angles, shapes, areas of the image). So it’s nearly an impossible task for a human to explicitly write a program to recognize an image. This was why progress was stalled for decades when it came to certain tasks. We were using the wrong tools.
The emergence of machines that learn
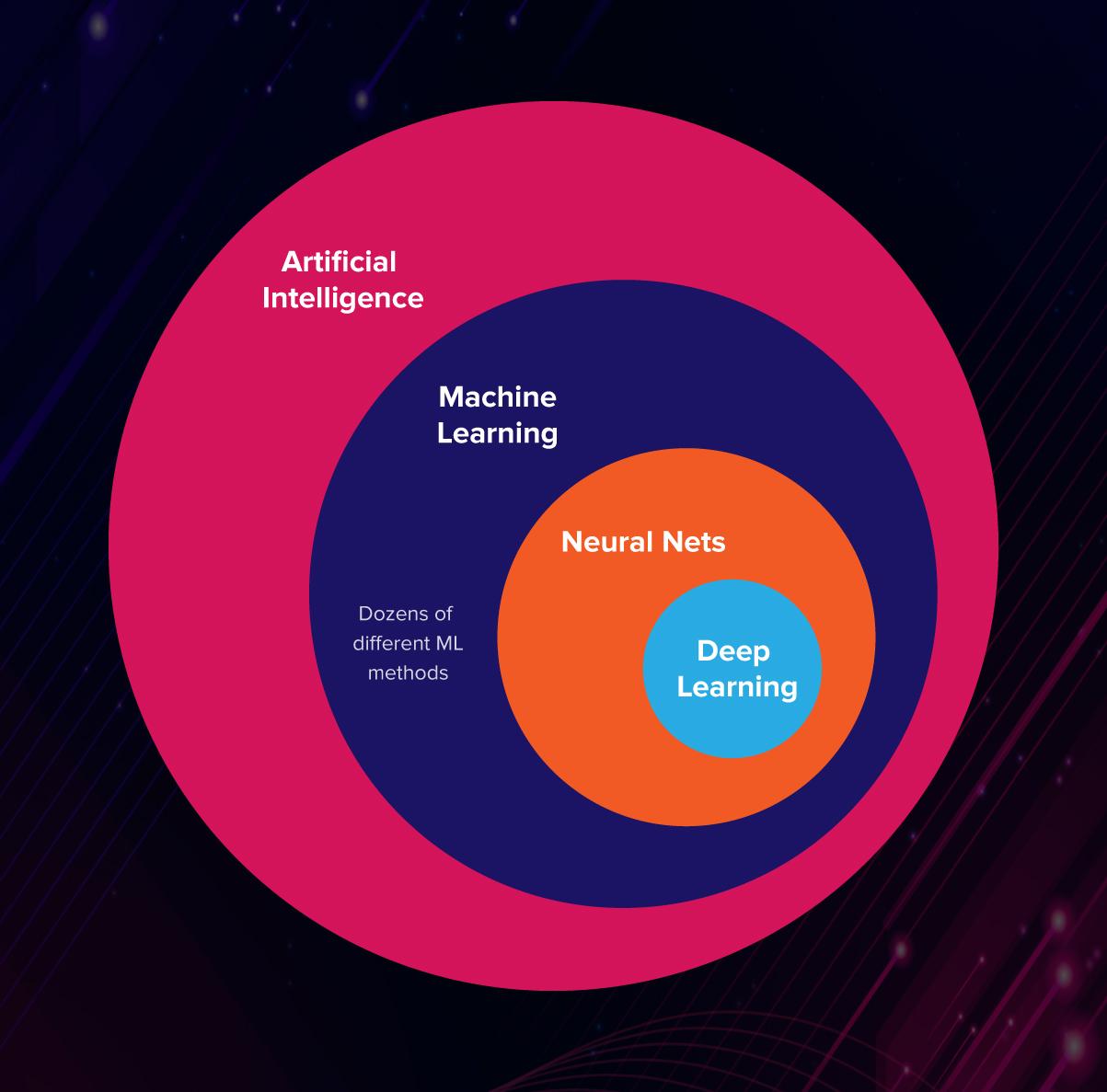
So what’s the magic sauce that makes “AI” intelligent? Most would agree that it’s the advent of machine learning, which is a subset of techniques within the AI category.
At its core, machine learning is a way to create algorithms that learn *mostly* through input data. Instead of writing code to tell the program how to detect when ears are cat shaped etc, you just feed it a bunch of pictures of cats and not-cats, and tell the algorithm which pictures are actually cats. The algorithm then adjusts itself accordingly, and the next time you feed it an image, it should give you the right answer. (This is example for supervised learning problems, we will ignore unsupervised learning for the time being)
I highlighted “mostly” because they still require some structure to base their new learning, so some design is required to create the most optimal algorithm that can learn from the specific data. This is commonly known as the “architecture”, but we’re jumping ahead here.
This was the crucial leap in the development of AI. Instead of writing every detail of the algorithm, we got machines to learn for themselves.
How it actually looks like
Before we dive into how neural networks are structured, or even simpler versions such as supervised learning for linear regression, it helps to build some intuition as to what these algorithms actually are. If you don’t really care, feel free to skip this section.
All this talk about “algorithms” and “machine learning” might sound abstract, so it might be helpful to peek a little under the hood. There’s a teeny bit of math-looking objects below, but I promise you’ll be able to follow even if looking at equations give you palpitations.
Remember learning about functions in math? A key part of any machine learning model can be described as some sort of function.
Here’s a simple one:
f(x) = 1.5x + 2
This is a simple linear function, but essentially it takes a value of x and spits out a value of f(x) or y. Put in x=5 and you’ll get 9.5. Most of information processing follows this simple process. Take a certain input, apply it through a function, and get a result.
x => f(x) => y
All machine learning models (or predictive models for that matter) are some form of polynomial functions, where they take a set of input and churn out a set of values that are then interpreted as a result. Whether it’s a large language model like GPT4 or a cat recognizer algorithm, they all work on the same underlying principle.
In reality, the functions in machine learning models are very long and complicated polynomial equations.
y = ax^3 + bx^2 + cx + …..
The a, b, and c letters represent the parameters that get tuned during the machine learning process. When you feed the model more data, it gets “trained” and the parameters increase and decrease accordingly, eventually converging on an efficient solution. The higher the quantity and quality of the data sets, the more accurate the model will become.

Early machine learning techniques
As described earlier, traditional programming quickly ran into problems with its strict, rule-based explicit programming approach. Then came the birth of new ML algorithms such as decision trees, logistic regression, and support vector machines. These algorithms learned from data and did not require explicit programming for each task.
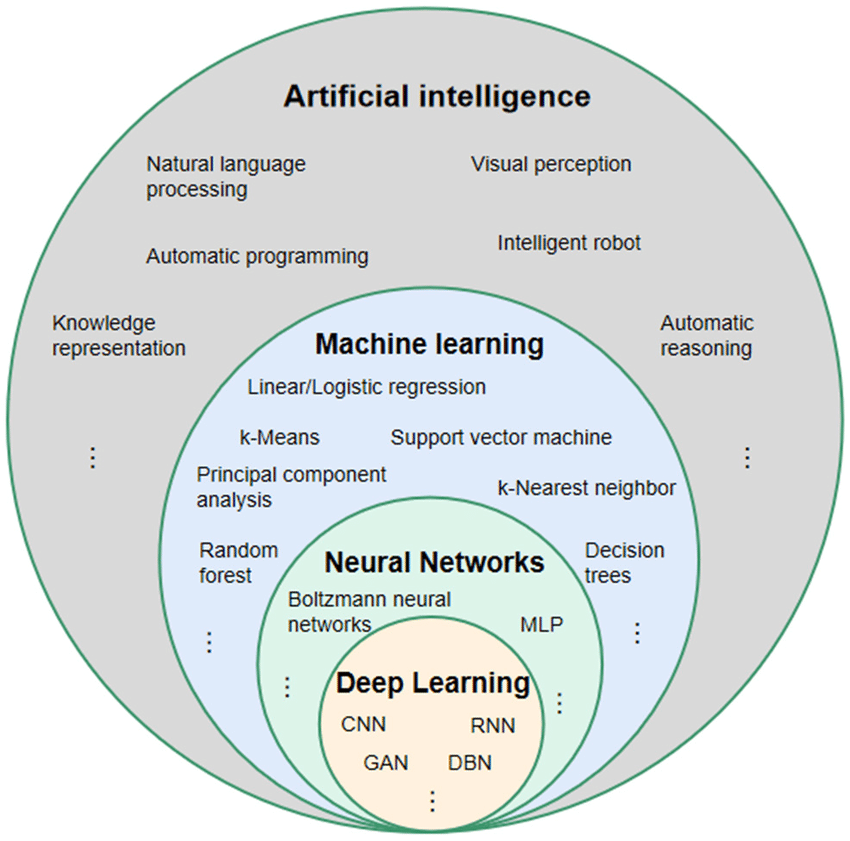
Source: https://www.researchgate.net/figure/Relationship-between-artificial-intelligence-machine-learning-neural-network-and-deep_fig3_354124420
These techniques are all still in use today, but they tend to work best for specific domains and less complex data sets. Image recognition and language models were too demanding for these techniques, and the field languished for another few decades.
The neural network revolution
Then came the era of neural networks. Well technically, the second coming of neural networks. Neural nets were developed in the early 1980s but basically went nowhere until the mid-2000s (this period was ominously dubbed as “AI winter”).
Neural networks are another type of machine learning model that’s loosely inspired by the human brain. I use the term “loosely” because other than the fact that they are connected into a network and take input/outputs, they have very little resemblance to how actual neurons function. These all-purpose algorithms proved to be more powerful than anyone anticipated, outpacing other algorithms in terms of performance and accuracy, eventually leading to the revolution we’re still experiencing today.
There are 3 main reasons behind the rise of neural networks
Better architecture: Theoretical advancements with techniques like back-propagation
More data: Models need a vast amount of data for them to “self-tune” themselves. Larger training sets from the growth of the internet provided more fuel for models to learn
More computing power: Training models are very computationally expensive. The increase in computing power and use of GPUs (instead of CPUs) which unlocked parallel processing made it feasible to train ever larger models.
How do neural networks work?
Below is a visualization of a simple neural network. Some basics to note:
- The dots are called nodes and the lines represent connections between nodes.
- Every connection to a node has a “weight”, which tells each node how strong the connection should be (which is similar to a parameter mentioned previously).
- The term deep learning is a way to describe neural networks with many layers
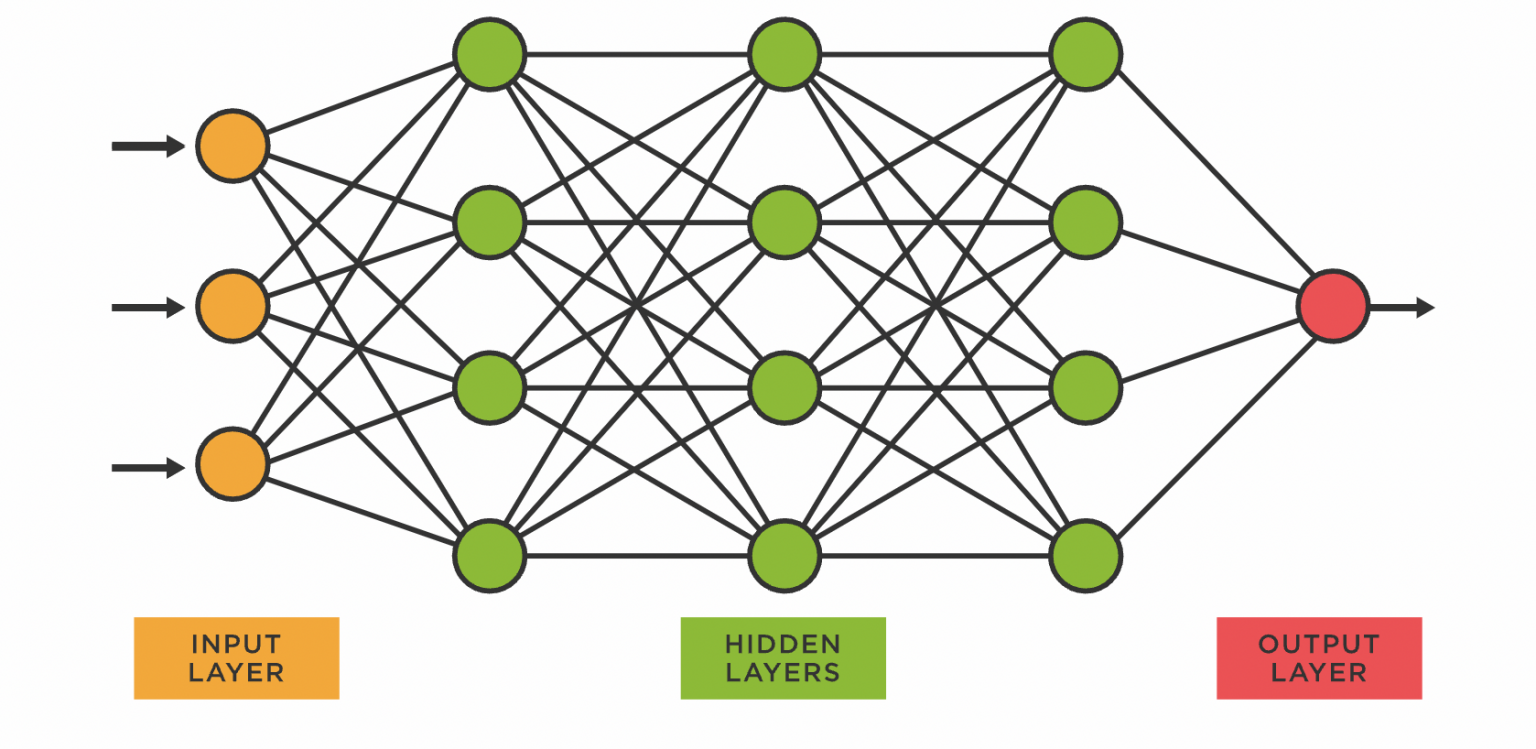
Here’s how the series of steps work for a neural network to identify if an image is a cat.
- Data flows forward from the input layer. (An image is transformed into pixel values and fed into the input layer)
- When an incoming input reaches a node, it will take the input and multiply it by the weight.
- The node will then sum all the associated weights, add a bias (another parameter) and provide an output (typically transformed by a ReLu or sigmoid function, but not entirely important here).
- The values cascade through the network until they converge on the output layer, producing a result (a value ranging from 0 to 1, with 0 being not cat and 1 being cat)
And that’s how neural network models are used. The key part of machine learning comes from the actual training of these models to get the appropriate weights. During the training phase, data is fed into the input layers and the model self-optimizes over many training sets to “learn” the best parameters (the procedure involves calculating a cost function, using gradient descent to find the necessary change, and back-propagating the values to update the parameters).
Under the hood, they work the same way as any function. Each node is actually a function (y=x1+x2…) that takes in several inputs and outputs to other nodes. They all connect together and essentially create a large complex function. In reality, machine learning is a fancy repackaging of calculus and statistics.
The neural network zoo
Once neural networks were created, people started to realize that there was an endless landscape of network permutations. Some worked better for certain tasks than others.
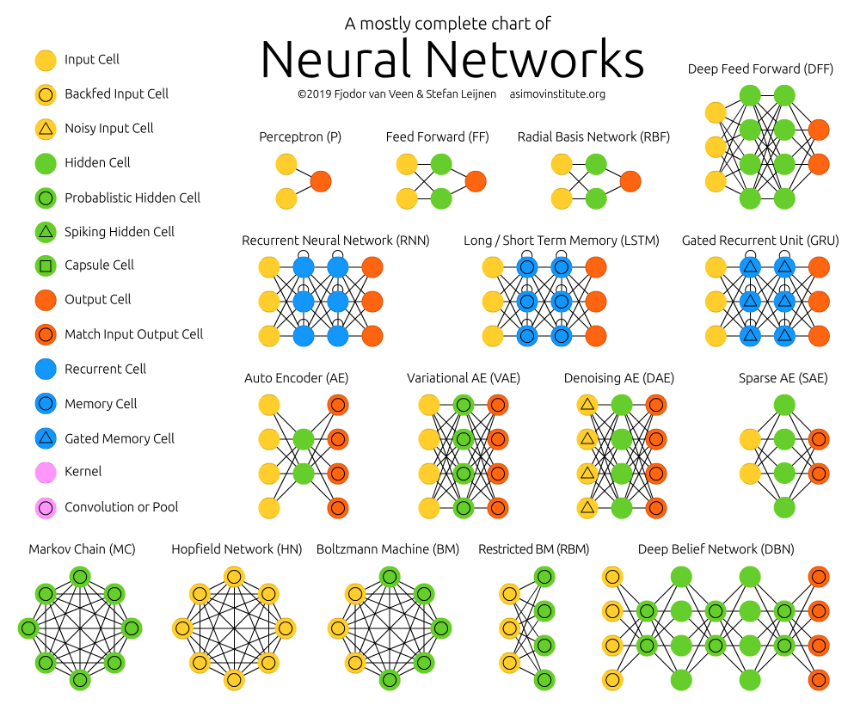
Popular ones in the last decade include convolutional neural networks for image recognition, RNNs LSTMs, and so on. I will not go into details here because another type of architecture emerged that took the world by storm.
Attention is all you need - the road to GPT
For many years, neural networks became progressively better at certain tasks like image recognition and games. Natural language processing, which requires the handling of long sequential data and faced issues like the vanishing gradient problem, languished on the sidelines while its peers outperformed on other tasks.
Then in 2017, the paper “Attention is All You Need” by Vaswani et al was released, and it changed the game by introducing the concept of transformer architecture. In very basic terms, it makes use of a mechanism called “attention,” which allows the model to weigh and refer to different parts of the input sequence while generating output. This breakthrough allows the model to consider all words at once and understand the context of surrounding words.
This gave rise to the large language models of today like GPT-4, which uses the underlying transformer architecture and the corpus of internet data as its training set.
The singularity
Now you should have a basic understanding of some of the key concepts. To summarise:
Machine learning is just a subfield of AI that uses self-learning algorithms
Neural networks are a subset of machine-learning techniques that have nodes and connections mimicking the brain
Large language models like GPT are based on transformer architectures, which are a new form of neural networks
Everything is ultimately made up of algorithms and functions
Where will all of this lead to? It’s impossible to predict for now, but needless to say, it’s gonna be one heck of a journey - as long as we don’t find ourselves creating an unaligned superintelligence at the end of it.